

단층 신경망 Single-Layer Perceptron
- input layer와 outoput layer 로만 구성
- 선형으로 이루어짐

단층 신경망의 한계
- 선형 분리 불가능(linearly inseparable) 문제
- 직선으로 영역을 분리할 수 없는 경우가 있음
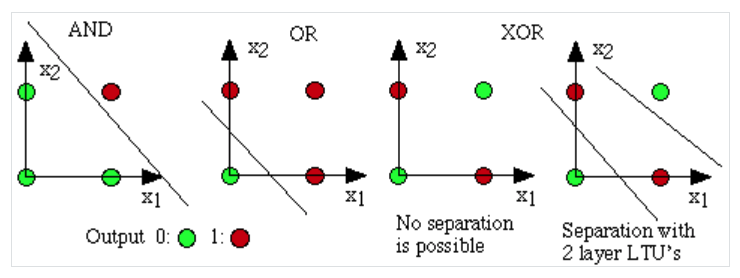
- 이러한 경우 아래 그림과 같이 복잡한 곡선으로만 영역 분리 가능함
- 선형분류기에서 비선형 분류기로 비꿔야하는 필요성 있음
- 이를 해결하기 위해 나온 개념이 hidden layer

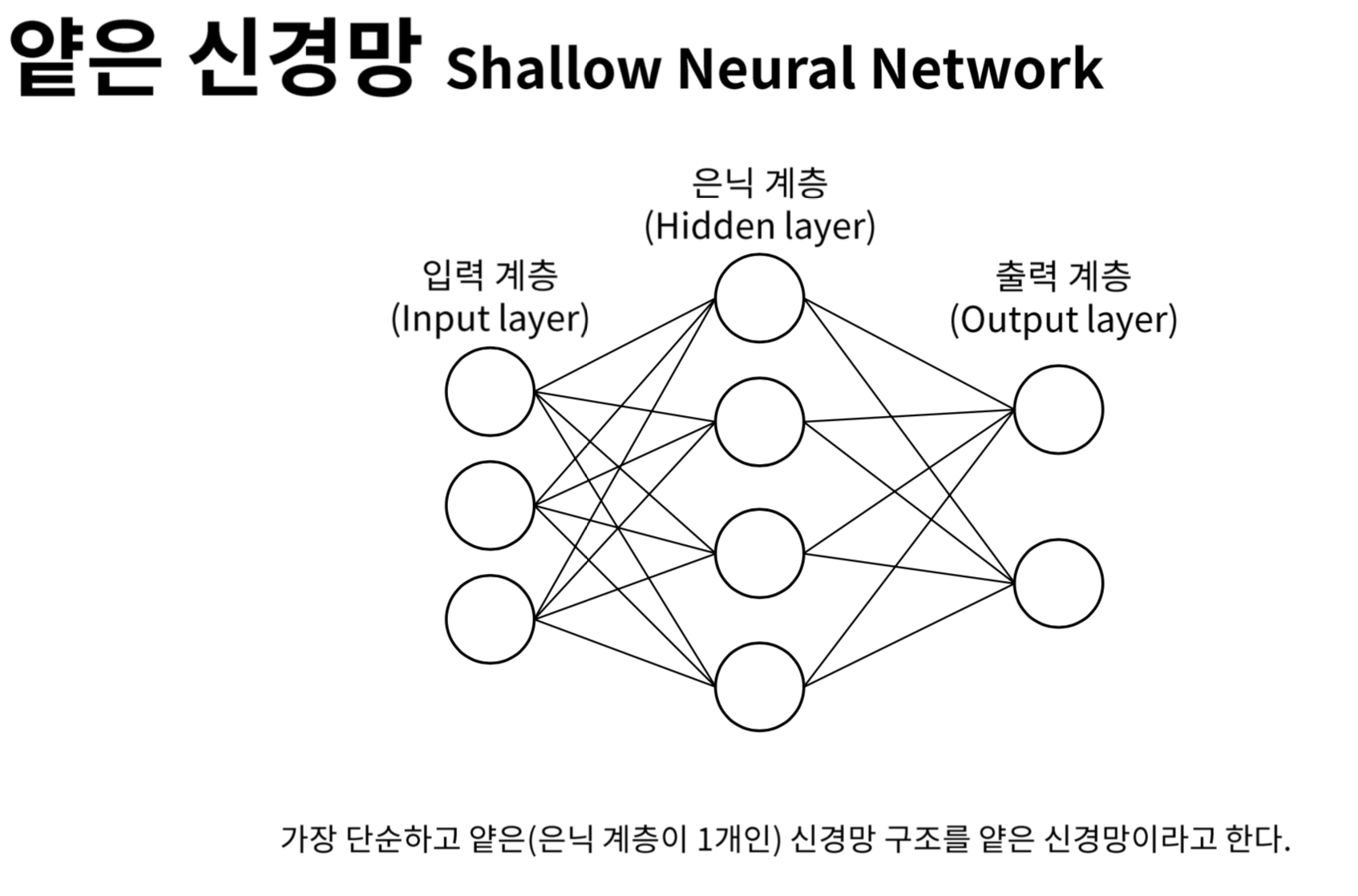
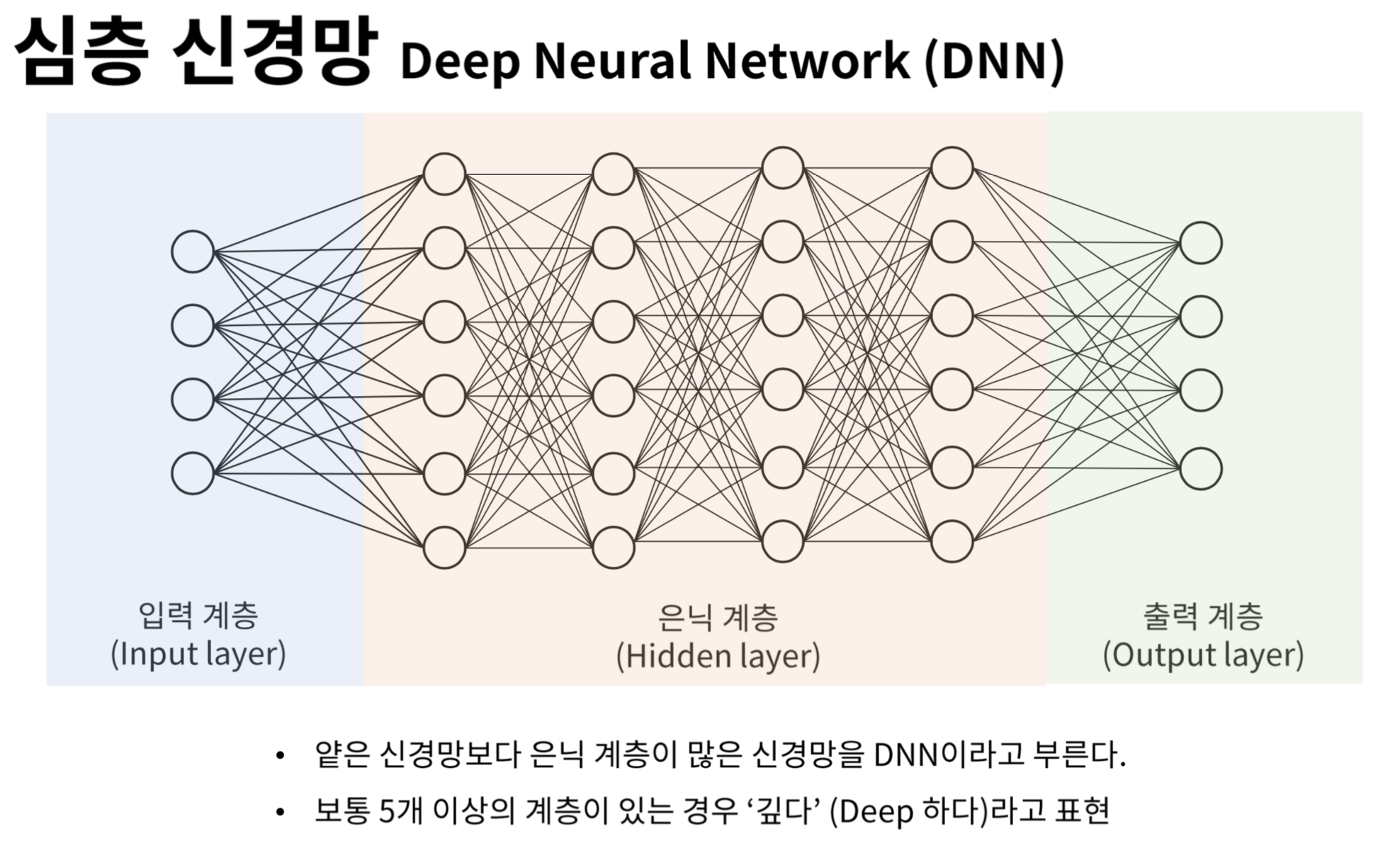
심층신경망 특징
- hidden layer가 2개 이상 부터는 심층신경망
- 비선형의 활성함수
- hidden layer도 무작정 쌓기만 한다고 해서 퍼셉트론을 선형분류기에서 비선형분류기로 바꿀 수 있는 것은 아님
- 2개의 Layer를 쌓아봤지만 X에 곱해지는 항들은 W로 치환가능하고, 입력과 무관한 상수들은 전체를 B로 치환 가능하기 때문에 WX+B라는 Single layer perceptron과 동일한 결과
- Deep 하게 쌓는 의미가 없어짐

활성화 함수activation function
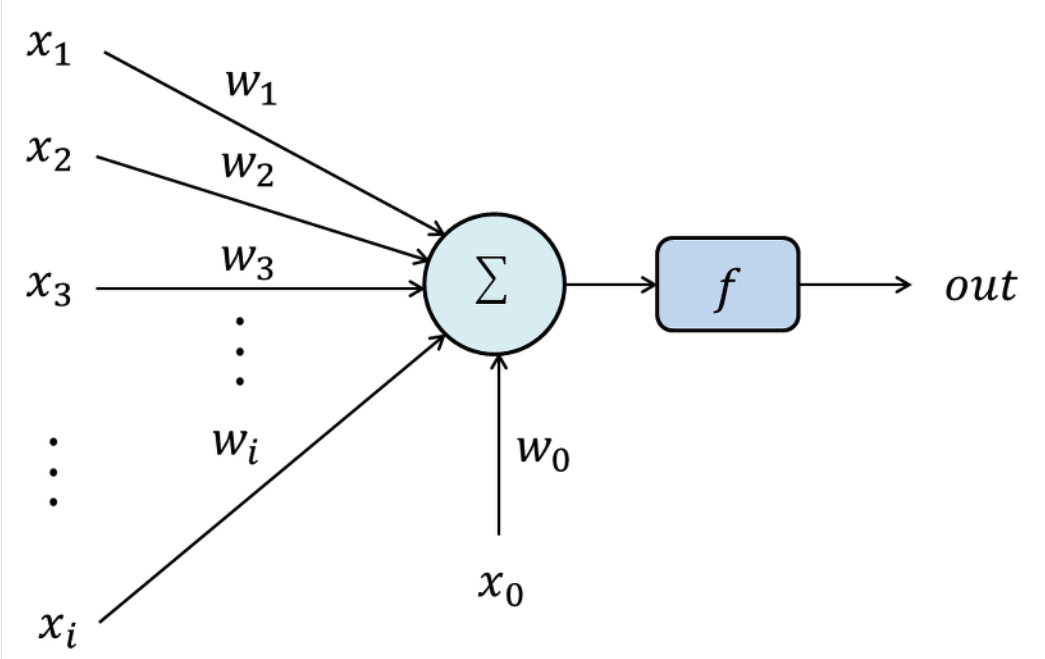
활성화 함수의 종류

한계
- non-linear 문제들은 해결할 수 있었지만 layer가 깊어질수록 파라미터의 개수가 급등하게 되고 이 파라미터들을 적절하게 학습시키는 것이 매우 어려움
- 이는 역전파 알고리즘이 등장하게 되면서 해결되었고 결론적으로 여러 layer를 쌓은 신경망 모델 학습이 가능
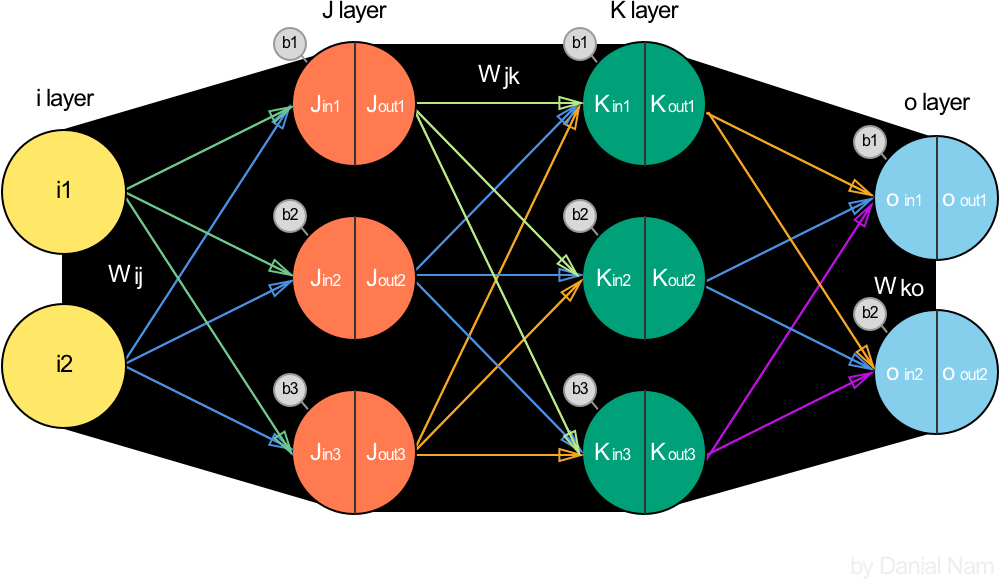
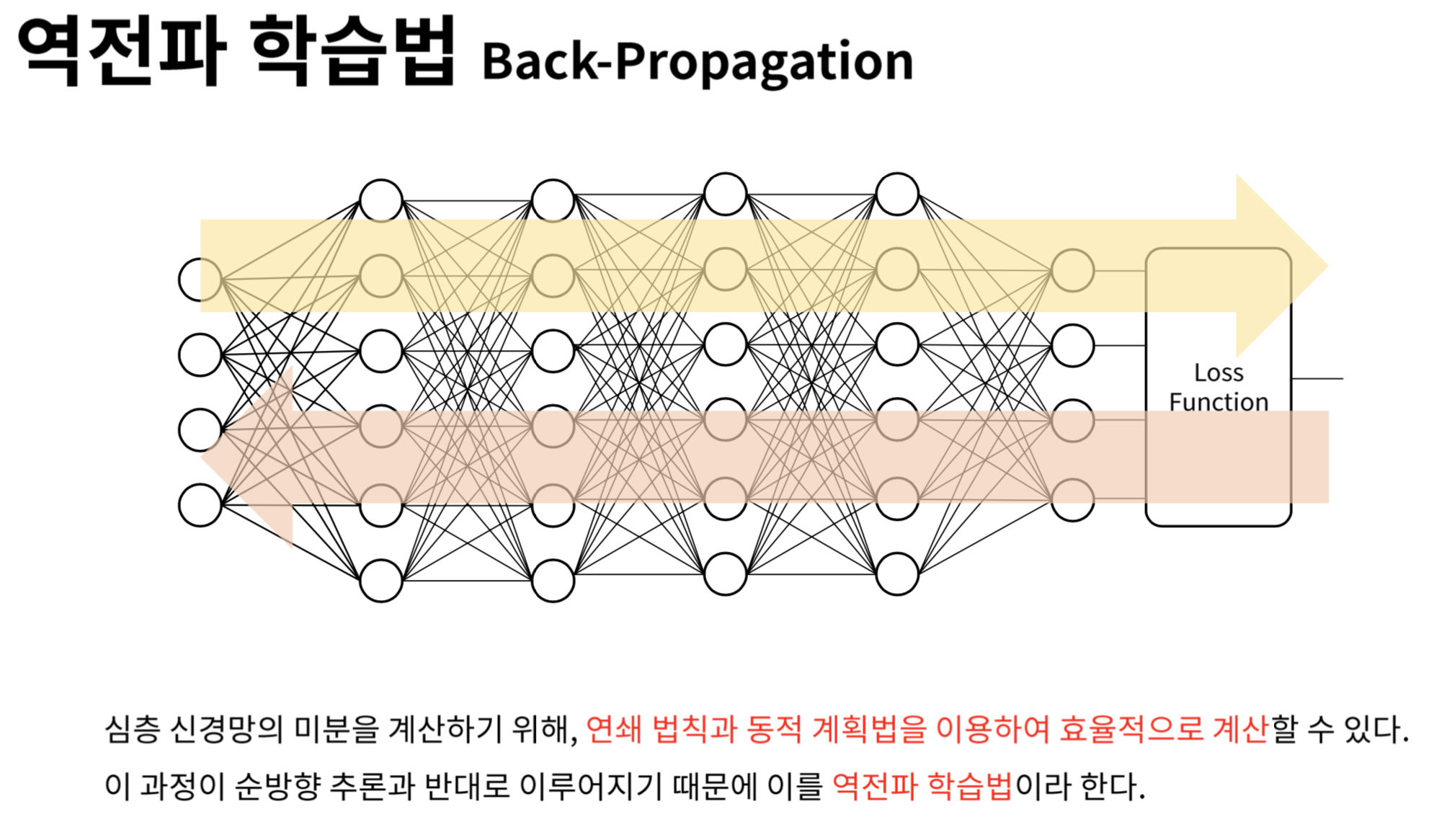
역전파 Backpropagation
- 역전파 알고리즘은 출력값에 대한 입력값의 기울기(미분값)을 출력층 layer에서부터 계산하여 거꾸로 전파시키는 것
- 출력층 바로 전 layer에서부터 기울기(미분값)을 계산하고 이를 점점 거꾸로 전파시키면서 전 layer들에서의 기울기와 서로 곱하는 형식으로 나아가면 최종적으로 출력층의 output에 대한 입력층에서의 input의 기울기(미분값)을 구할 수가 있음

배치 Batch
- Iteration 1회당 사용되는 training data set 의 묶음
미니배치sub>Mini-Batch
- training data set 쪼개어 놓은 묶음

Batch gradient descent(BGD)
- 전체 데이터 셋에 대한 에러를 구한 뒤 기울기를 한번만 계산하여 모델의 parameter 를 업데이트 하는 방법
확률적 경사 하강법 Stochastic gradient descent(SGD)
- 추출된 데이터 한 개에 대해서 error gradient 를 계산하고, Gradient descent 알고리즘을 적용하는 방법
- 전체 데이터를 사용하는 것이 아니라, 랜덤하게 추출한 일부 데이터를 사용
- 따라서 학습 중간 과정에서 결과의 진폭이 크고 불안정하며, 속도가 매우 빠르다.
