

- 트레이닝 세트와 검증세트 나누기
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = keras.datasets.fashion_mnist.load_data()
train_scaled = train_input / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size = 0.2, random_state=42
)
- 모델을 만드는 함수 생성
def model_fn(a_layer=None):
model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(100, activation = "relu"))
if a_layer:
model.add(a_layer)
model.add(keras.layers.Dense(10, activation="softmax"))
return model
model = model_fn()
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
dense_1 (Dense) (None, 100) 78500
dense_2 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
model.compile(loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=5, verbose=0)
history.history
{'loss': [0.5299330353736877,
0.3862016499042511,
0.35116592049598694,
0.3301049470901489,
0.3153148293495178],
'accuracy': [0.8133958578109741,
0.8612083196640015,
0.8732500076293945,
0.8815833330154419,
0.8871250152587891]}
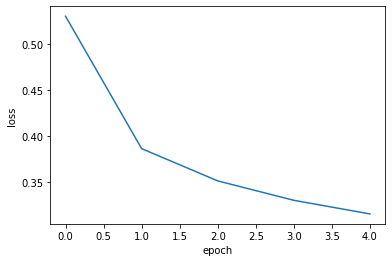
손실 곡선
import matplotlib.pyplot as plt
- 각 에포크마다 측정된 loss 값
plt.plot(history.history["loss"])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
- 각 에포크마다 측정된 정확도
plt.plot(history.history["accuracy"])
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.show()
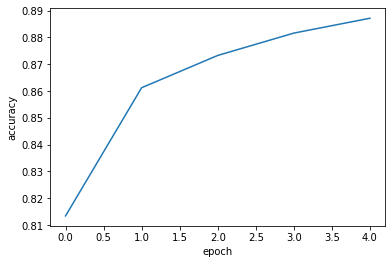
- 에포크가 늘어날 수록 loss 줄고 accuracy 늘어남
- epoch를 20으로 올렸더니 손실 잘 감소
- 과연 더 나은 모델을 훈련한 것일까?
model = model_fn()
model.compile(loss="sparse_categorical_crossentropy", metrics = "accuracy")
history = model.fit(train_scaled, train_target, epochs=20, verbose = 0)
plt.plot(history.history['loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
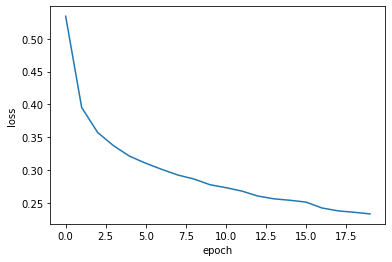
검증 손실
- 에포크에 대한 과대적합과 과소적합 파악하려면 훈련세트에 대한 점수 뿐만 아니라 검증 세트에 대한 점수도 필요
- fit 메서드에 validation_data 매개변수 추가하면 검증세트에 대한 loss와 accuracy도 알 수 있음
model = model_fn()
model.compile(loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
history.history.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
- 초기에 검증 손실이 감소하다가 다시 상승하기 시작
- 훈련손실은 꾸준히 감소하기 때문에 전형적인 과대적합 모델이 만들어짐
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()
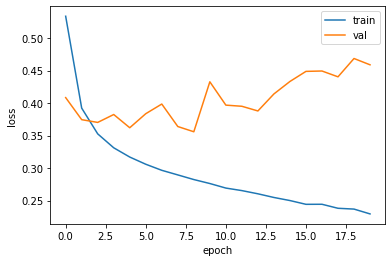
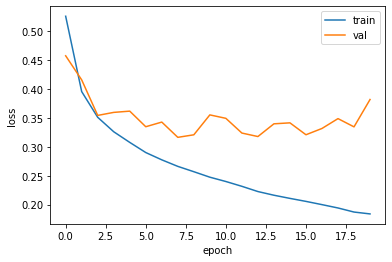
- optimizer 하이퍼파라미터를 조정하여 과대적합 완화시킬 수 있는가
- Adam은 적응적 학습률을 사용하기 때문에 에포크가 진행되면서 학습률의 크기 조정 가능
- overfitting 이 훨씬 줄었다
- 여전히 요동이 남아있긴 함
- 이는 Adam optimizer가 이 데이터셋에 잘 맞는다는 것을 의미
model = model_fn()
model.compile(optimizer ="adam", loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()
Dropout
- dropout : 훈련 과정에서 층에 있는 일부 뉴런을 랜덤하게 꺼서 overfitting 막음
- keras.layers 패키지 아래 Dropout 클래스로 제공
- 어떤 층 뒤에 둬서 이 층의 출력을 랜덤하게 0으로 만듬
- 층처럼 사용되지만 훈련되는 모델 파라미터는 X
- 일부 뉴런의 출력을 0으로 만들 뿐 전체 출력 배열의 크기를 바꾸지 X
model = model_fn(keras.layers.Dropout(0.3))
model.summary()
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_6 (Flatten) (None, 784) 0
dense_11 (Dense) (None, 100) 78500
dropout (Dropout) (None, 100) 0
dense_12 (Dense) (None, 10) 1010
=================================================================
Total params: 79,510
Trainable params: 79,510
Non-trainable params: 0
_________________________________________________________________
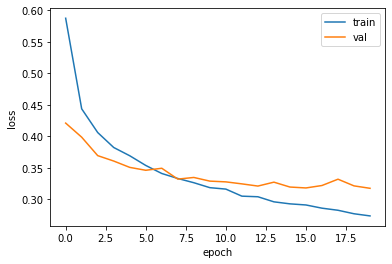
- 확실히 줄어든 overfitting
- 열 번째 에포크에서 검증 손실의 감소가 멈추지만 크게 상승하지 않고 어느 정도 유지 중
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=20, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()
모델 저장과 복원
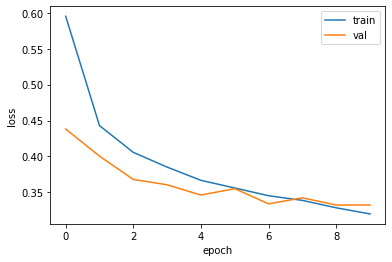
- 위의 실험 결과 10번이 최적
- 위의 모델을 에포크 횟수를 10으로 지정하고 다시 모델 훈련하기
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics="accuracy")
history = model.fit(train_scaled, train_target, epochs=10, verbose=0, validation_data=(val_scaled, val_target))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()
- save_weights : 훈련된 모델의 파라미터 저장
model.save_weights("model-weights.h5")
- save : 모델 구조와 모델 파라미터 함께 저장
model.save('model-whole.h5')
- 확인

두 가지 실험
- 훈련하지 않은 새로운 모델을 만들고 model-weights.h5 에서 훈련된 모델 파라미터 읽어서 사용
- 아예 model-whole.h5 파일에서 새로운 모델 만들어서 바로 사용
첫번째 실험
- load_weights() -> 모델 파라미터 적재하는 메서드
- 이 모델의 검증 정확도 확인
- 케라스에서의 predict 메서드 : 사이킷런과 다르게 10개 클래스에 대한 확률 반환
- 준비된 검증세트는 12000개 이므로 predict 메서드는 (12000,10) 크기의 배열 반환
model = model_fn(keras.layers.Dropout(0.3))
model.load_weights('model-weights.h5')
import numpy as np
val_labels = np.argmax(model.predict(val_scaled), axis=-1)
np.mean(val_labels==val_target)
0.8781666666666667
두번째 실험
model = keras.models.load_model('model-whole.h5')
model.evaluate(val_scaled, val_target)
375/375 [==============================] - 0s 833us/step - loss: 0.3325 - accuracy: 0.8782
[0.33252522349357605, 0.878166675567627]
결론
- 같은 모델을 저장하고 다시 불러들였기 때문에 동일한 정확도 얻음
- 불편한 점
- 20번의 에포크 동안 모델을 훈련하여 검증 점수가 상승하는 지점 확인
- 모델 과대적합되지 않는 에포크만큼 다시 훈련
- 두 번씩 훈련하지 않는 방법 없을까
콜백
- 콜백 : 훈련과정 중간에 어떤 작업을 수행할 수 있게 하는 객체
- ModelCheckpoint 콜백 : 기본적으로 최상의 검증 점수를 만드는 모델을 저장
- 하지만 여전히 20번의 에포크동안 훈련을 함
- 사실 검증 손실 점수가 상승하기 시작하면 overfitting이 커지기 때문에 훈련 계속할 필요 없음
- overfitting이 시작되기 전에 훈련 미리 종료하는 것 : Early stopping(조기 종료)
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5')
model.fit(
train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb]
)
model = keras.models.load_model('best-model.h5')
model.evaluate(val_scaled, val_target)
375/375 [==============================] - 0s 792us/step - loss: 0.3189 - accuracy: 0.8856
[0.3189184069633484, 0.8855833411216736]
Early Stopping
- 조기종료 : 과대적합이 커지기 전에 훈련을 미리 중지하는 것
- patience : 지정된 patience번 연속 검증 점수가 향상되지 않을 경우 훈련 종료
model = model_fn(keras.layers.Dropout(0.3))
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-model.h5')
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)
history = model.fit(
train_scaled, train_target, epochs=20, verbose=0,
validation_data=(val_scaled, val_target), callbacks=[checkpoint_cb, early_stopping_cb]
)
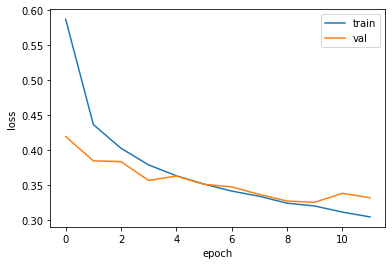
11번만에 종료
early_stopping_cb.stopped_epoch
11
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()
model.evaluate(val_scaled, val_target)
375/375 [==============================] - 0s 791us/step - loss: 0.3259 - accuracy: 0.8845
[0.3258848488330841, 0.8845000267028809]